
必赢官网发布两篇关于“大语言模型与软件工程任务”的新综述。站在大语言模型风口上的软件工程,将飘往何方?
565net必赢客户端InPlusLab团队于2023年8月22日和11月17日在arXiv上分别公布了两篇“大语言模型+软件工程”的综述:
https://arxiv.org/abs/2308.11396
https://arxiv.org/abs/2311.10372
当前,随着越来越多的专为软件工程任务设计的LLMs得到部署,也有越来越多研究工作聚焦于将LLMs在软件工程领域的应用和实例分析。LLM能否更好地解析需求,能否生成高质量的代码、高覆盖的测试用例等已成为软件工程领域的热门话题。然而,在现有文献中,不仅对于LLM在软件工程领域的应用和评估的调研工作存在缺失,对于专为软件工程任务设计的LLMs的演变、表现和发展方向也缺少系统性的回顾。565net必赢客户端InPlusLab团队公布的这两篇文章则分别针对这两点展开了系统性综述。

第一篇文章全面梳理了软件工程领域与LLM的结合点,并总结了当前LLM在软件工程任务上的表现情况,为LLM在软件工程领域的研究和优化提供了基础性建议。根据当前行业对大模型中“大”的定义以及LLM的时效性,文章分别从ACM Digital Library,IEEE Xplore Digital Library和arXiv等六个主要文献数据库中收集并筛选出了2022年以来的123篇相关文献。主要针对下面两个问题展开:
1. RQ1: 当前LLM与软件工程有哪些结合性工作?它们关注于软件工程中的哪些任务?
2. RQ2: 当前LLM在软件工程任务上的表现如何?以及对未来工作的一些讨论。
RQ1: 对当前文献中LLM
与软件工程研究点的回顾
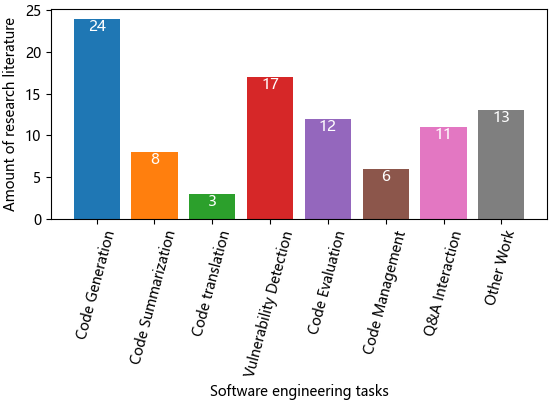
文章将筛选出的123篇论文根据涉及的软件工程任务的具体内容进行了分类,主要包括七个类别:代码生成(Code Generation)、代码摘要(Code Summarization)、代码翻译(Code Translation)、漏洞检测(Vulnerability Detection)、代码评估(Code Evaluation)、代码管理(Code Management)和问答交互(Q&A Interaction)。并展示了分类后文献的分布情况(如下图所示),其中面向代码生成(Code Generation)的研究相对较多,而面向代码翻译(Code translation)的最少,面向其他软件工程任务的数量相对较为平均。
针对每个类别,文章给出了它们的定义并在正文中详细阐述了示例和当前的研究工作,这可以帮助研究人员在将LLM应用于软件工程任务时继续发现和解决潜在问题。在代码生成任务上,当前的研究工作主要分为三个方向:评估工作、发布全新的测试框架或方法、增强的大语言模型的代码生成能力。
在问答交互任务上,当前工作则主要集中于开发原型系统或交互框架、评估工作、提示工程以及问答交互时安全性和效率问题的改进。

虽然在软件工程领域中,软件评估和漏洞挖掘存在一定的交集。但由于它们在LLM上的应用侧重不同,所以文章也进行了分别讨论。在软件评估方面,当前工作主要集中于测试用例生成、提出代码测试框架、测试助手或代码测试模型;在漏洞挖掘方面,则主要关注评估工作、正确性和效率问题的改进及应用的研究。
当前工作在代码摘要上的研究方向和在代码生成上的比较接近,主要方向分别是评估工作、应用研究和增强LLM的代码摘要能力;而在代码翻译任务上工作较少,仅有的三个工作聚焦于逆向工程与应用。
同时,还有一些工作将LLM用于代码管理,主要分为辅助代码合并和代码版本管理。
文章还对其他一些相关工作进行了展示,如性别取向、数据虚拟化等。

RQ2: 对当前LLM在软件工程任务上的
性能表现进行回顾
尽管LLM在文本生成任务上有优秀的表现,但其在代码生成等软件工程任务上的表现还需要进一步验证。在这部分,文章对上述文献中含有评估内容的论文进行了筛选。考虑到不同评估工作采用的LLM和关注的软件工程任务可能不同,所以文章在筛选时也对这些信息进行了整理(如下表所示)。文章主要从摘要和结论中筛选出文章的评估结果,并按结果分为:Finished Well, Poor Proformance和Ambiguity。需要注意的是,蓝色阴影代表虽然文章评测的LLM(s)在该任务上表现不好,但是文献中依然给出来积极的态度;红色阴影代表评估结果不错,但仍然存在限制,甚至是不够好。
文章对以上结果进行讨论,并初步得出结论:(1)代码生成作为一个较难的任务,目前LLMs在这个任务上往往并不能达到“可直接使用”的程度,表现也并不优异和统一。但一些文章中虽然评估的结论并没有对LLMs作出肯定,还是给出了积极的态度;(2)在程序修复、Text-to-SQL这些任务上,LLM通常能做的很好;(3)在程序漏洞检测上,LLMs通常表现得并不好;(4)虽然有两篇文献关于LLMs在测试用例生成这一任务上的结论存在矛盾,但它们也都给出了比较积极的态度,认为LLMs在这项任务上具有潜力;(5)在代码总结、代码解释任务上,LLMs通常具有很好的表现,但在鲁棒性上有所欠缺;(6)比较新的LLMs在代码生成这项任务上的表现进步很大。
文章得到一个最基本的结论:LLMs在一些需要理解代码语法的软件工程任务上,如代码摘要、代码修复,获得了很好的表现;但在一些需要理解代码语义的软件工程任务上,如代码生成、漏洞检测,通常表现的不够好;LLMs随着版本/模型的迭代依然在不断进步,是具有潜力的。所以,文章认为在当前阶段,LLMs依然不能代替人工进行软件工程任务,但是它能成为一个很好的程序开发者助理、搜索器和提示工具。

第二篇文章对代码LLM(Code LLMs) 的发展历程和性能表现进行了全面调查和分析,包括Code LLMs与通用LLMs之间的性能,以及Code LLMs之间的性能表现。文章的动机为:Code LLMs可以通过指令微调的方法产生,也可以通过传统的预训练方法得到。身为专门为软件工程领域开发的语言模型,理想情况下,LLMs在软件工程任务上的能力通常可以得到进一步激发,并拥有更强的代码生成、漏洞挖掘等能力。所以,当前也有大量工作聚焦于此,并产生许多具有里程碑意义的Code LLMs,如Codex、StarCoder、Code Llama等。但是,由于指令微调、训练数据等各方面带来的不确定因素,以及当前最先进的通用LLMs,如GPT-4,在各个软件工程领域取得了瞩目的效果。我们很难确定当前最先进的Code LLMs在软件工程任务上能否比当前最先进的通用LLMs获得更好的表现。同时,Code LLMs的数量繁多,它们很大一部分都是通过在通用LLMs或其他Code LLMs上微调得到。由于它们可能拥有不同的结构和微调技术,所以很可能不同Code LLMs擅长的软件工程任务并不相同。然而,目前却缺少对Code LLMs及其性能的系统性调查,尤其是Code LLMs与通用LLMs、以及Code LLMs之间的性能调查。
为此,文章从GitHub, dblp, Google Scholar和 arXiv四个主要的发布新模型的数据库中筛出了134篇有效的相关文献。文章主要针对下面三个问题展开:
1. RQ1: 当前有哪些专为软件工程任务设计的LLMs?它们是如何演变的?
2. RQ2: 这些Code LLMs在软件工程任务上的性能表现比通用LLMs更好吗?
3. RQ3: 在不同软件工程任务上,不同Code LLMs的表现如何?
RQ1: 当前有哪些专为软件工程任务
设计的LLMs?它们是如何演变的?
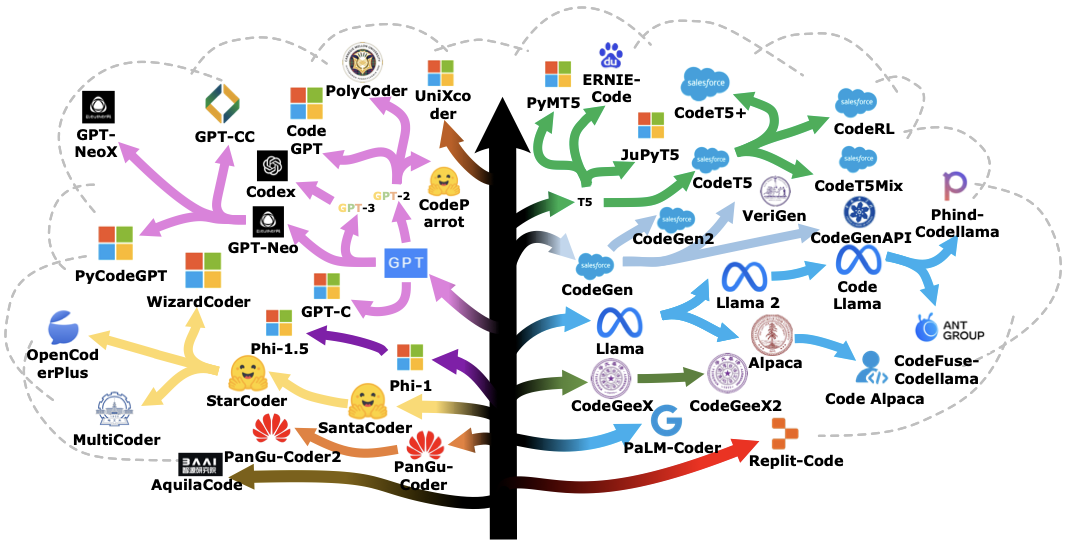
文章将收集到的专为软件工程任务设计的LLMs(Code LLMs)进行整理并展示了它们之间的关系。下图根据发布单位统计了Code LLMs的数量。我们可以看到,企业主导的Code LLMs有18个,其中微软发布最多,占8个;高校共发布18个Code LLMs;相对来说,研究团队和社区发布的Code LLMs最多,有21个。
文章也按照发布的时间对Code LLMs进行了展示(如下图所示)。其中红色表示未开源,蓝色表示开源。我们可以看到随着年份的增加,越来越多的企业、高校和科研团队参与到Code LLMs的开发中。

文章还梳理了这些Code LLMs之间的关系(如下图所示)。其中箭头表示被指向者由指向者发展得到,这种发展包括且不限于:改良、微调、借用技术。
RQ2: 这些Code LLMs在软件工程任务上
的性能表现比通用LLMs更好吗?
文章从收集的论文中筛选出对Code LLMs进行评测、发布全新评测基准以及全新Code LLMs的文章。并从全部文献中筛查出实验部分存在Code LLMs与通用 LLMs对比工作的内容,最终得到如下图的结果:
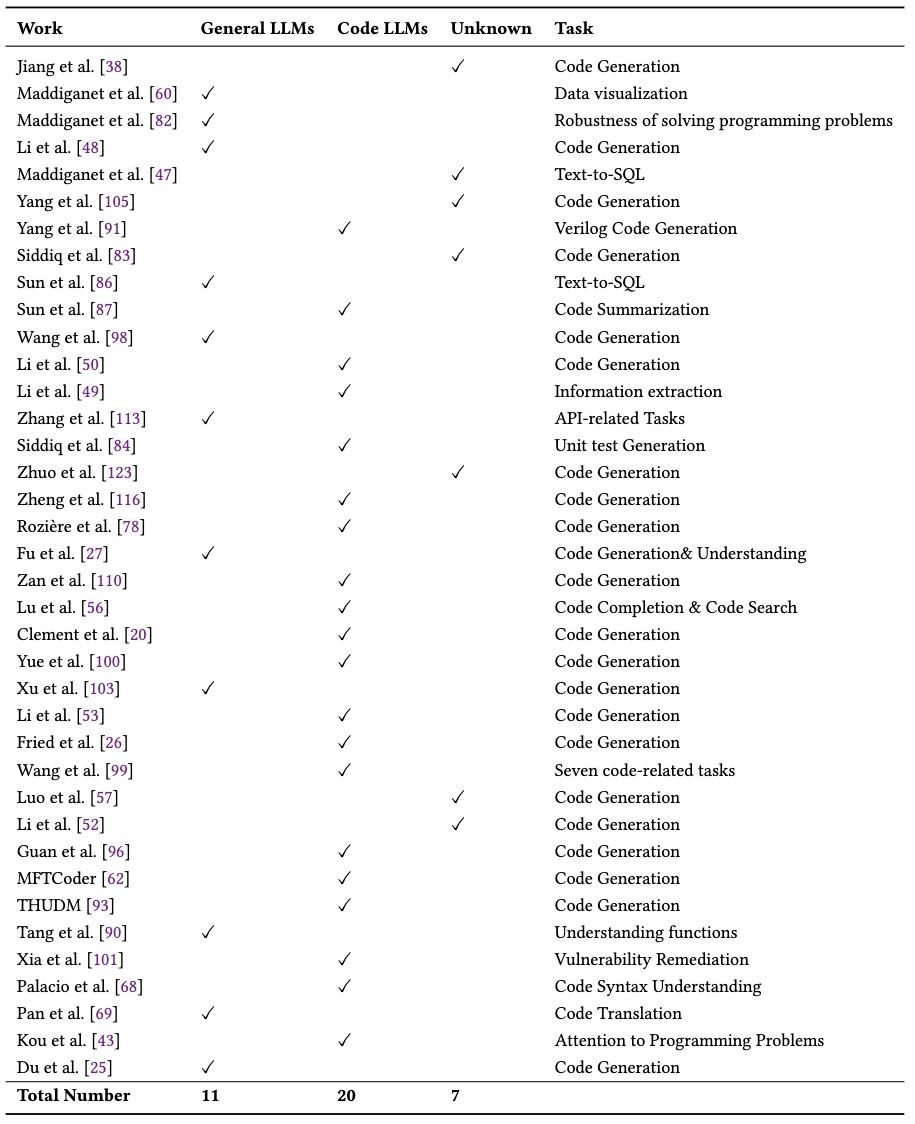
在上表的38篇文献中,共有11篇工作中的实验显示通用LLMs在软件工程任务上的表现更好,而有20篇工作的实验部分,显示Code LLMs表现更优秀。还有7篇文章,我们无法从其中的实验部分或文章结论中得到关于Code LLMs与通用LLMs谁更好的明确结论。
根据上述文献的结果,我们可以得到如下结论:(1)模型的参数对模型的性能影响非常大,同一模型的较大规模往往具有更好的表现;(2)对于同一模型,面向软件工程任务进行指令微调后的新模型比基座模型具有更好的表现;(3)在参数量接近时,Code LLMs往往比通用LLMs表现更好;(4)当前最先进的Code LLM比当前最先进的通用LLMs(GPT-4)在代码生成任务上表现更好。
文章还分享了一些有趣的结果:(1)同一模型的参数规模对模型的能力存在重要的影响,但在影响程度上,不同LLMs的表现可能存在差异,模型参数量对于模型性能是否存在边际效应,以及不同模型对于参数量的敏感程度,或许是一个值得讨论的问题。(2)所有的编码器-解码器模型的HumanEval结果都比仅解码器模型差的多。可能是因为:编码器-解码器与HumanEval设置不太一致,但是仅编码器模型却与竞赛编程设置非常一致。所以,文章认为我们可能还需要更加多样化的测试基准来量化Code LLMs的真实能力,单一的benchmark可能并不能完整体现LLMs的性能。(3)LLM的能力不完全由其规模决定,数据质量可能发挥着非常重要的作用。所以phi-1.5-1.3B才有可能战胜参数规模五倍于它的LLMs。
当然,我们也发现,当前在实际的应用中评估Code LLMs和通用LLMs的性能表现比较困难。一个最主要的原因是当前最先进的通用LLMs——GPT-4和GPT-3.5-tubro未开源,所以很多测试都没有将这两个LLMs进行对比。并且,由于每个工作的发表时间不同,每个工作所能采用的Code LLMs与通用LLMs也几乎不相同,这便导致各个工作的评测结果存在差异。
RQ3: 在不同软件工程任务上,
不同Code LLMs的表现如何?
文章首先从收集的论文中整理出具有对LLMs在软件工程任务上评测的部分,并将这些工作面向不同的软件工程任务进行分类,再按评测的benchmark进行分类,文章希望可以为每一个benchmark整理出一个相对较为完整的名单。
文章在这一部分不仅整理了包含HumanEval、MBPP等主流Benchmark的较为完整的名单,还将不同文献中的大量数据进行整理和展示。并且文章针对Code LLMs的表现进行了阐述,给出了如下结论:(1)当前针对LLMs的评估更关注代码生成任务,对于其他任务的评估或关注度较少。不仅相关评估工作存在缺失,在新模型发布时,也鲜少关注漏洞修复等任务。(2)对于代码生成任务存在HumanEval等广受关注的benchmark,而其他任务上缺少这样的benchmark;在代码生成任务上,Code-LLaMA系列的LLMs表现得最好,其中Unnatural-Code-LLaMA-34B的表现最突出;在API相关的代码生成任务上,ToolCoder表现更好,而GPT-4、GPT-3.5(GPT-3.5-turbo)也具有很好的性能表现。(3)在测试用例生成任务上,GPT-4和GPT-3.5(GPT-3.5-turbo)具有更好的性能表现。(4)在代码摘要任务上,CodeT5+具有更好的性能表现,好于GPT-3.5(GPT-3.5-turbo)。(5)在代码翻译任务上,GPT-4的表现更好。(6)在漏洞修复任务上,根据仅有的一些结果,Codex的性能更好。
565net必赢客户端发布的这两篇论文围绕“大语言模型+软件工程”主题,不仅全面梳理了软件工程领域与LLM的结合点、总结了当前LLM在软件工程任务上的表现情况,也对代码 LLM(Code LLMs)的发展历程和性能表现进行了全面调查和分析。两篇文章对范围内历史工作进行系统回顾的同时,也对该主题的发展方向进行了讨论,比如Code LLMs的性能改进方向等,值得关注!

